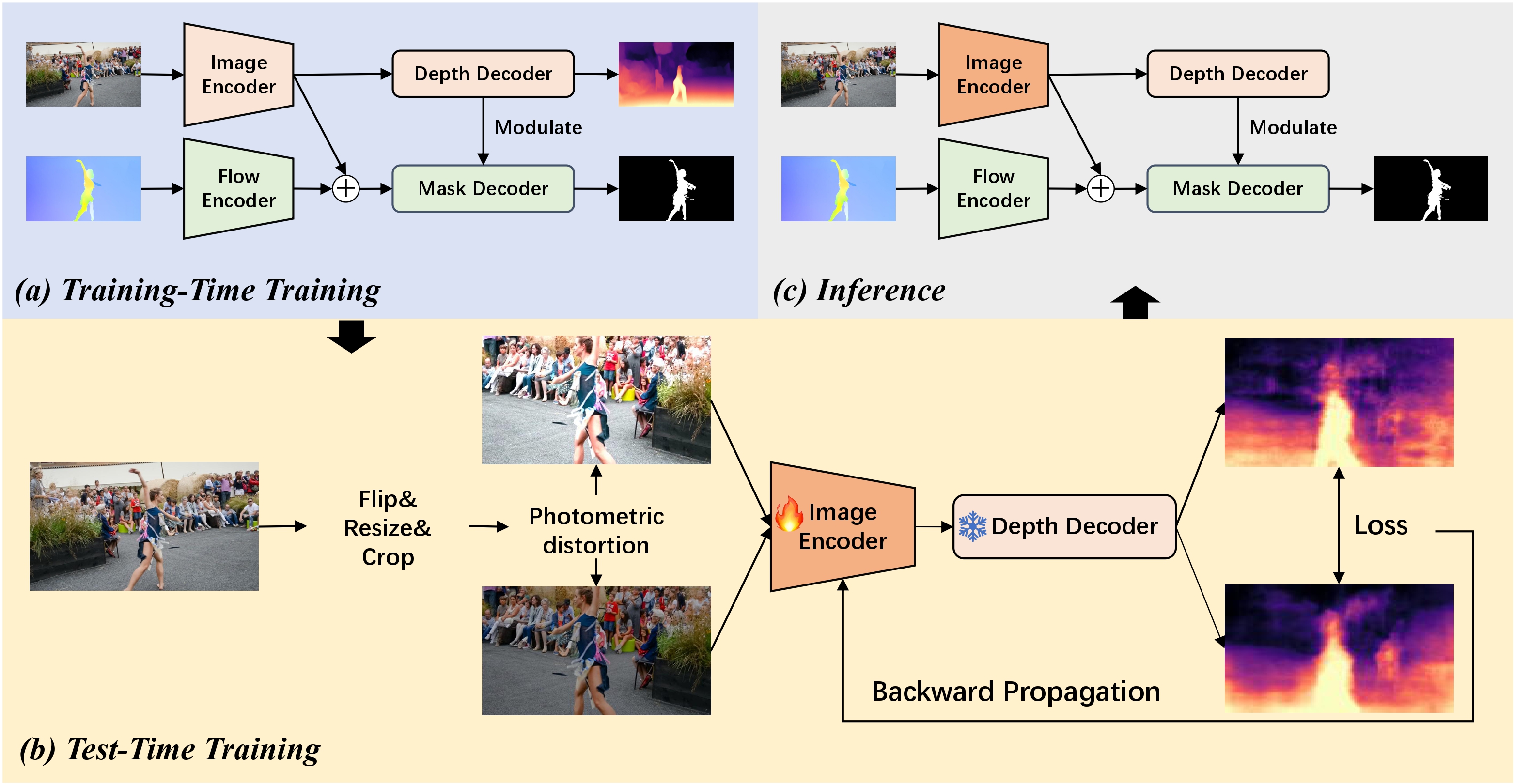
Overview
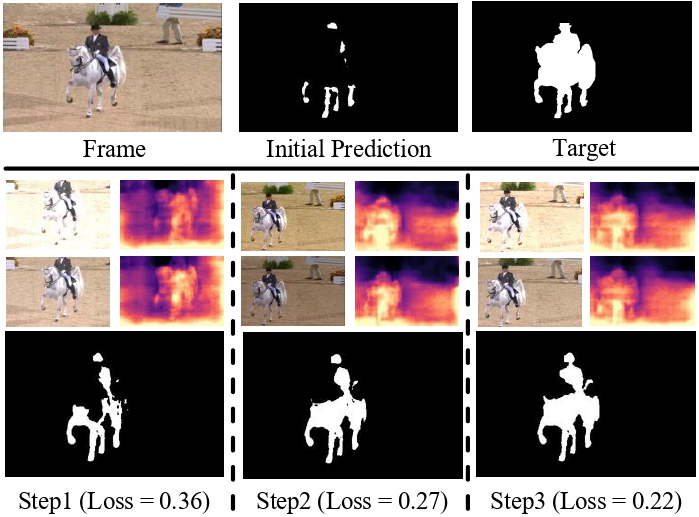
Our key insight is to enforce the model to predict consistent depth during the TTT process. During the test-time training, the model is required to predict consistent depth maps for the same video frame under different data augmentation. The model is progressively updated and provides more precise mask prediction.